
After the police killing of George Floyd in May 2020 and the resulting historic, global protests, Adam Poliak wanted to know more about people’s attitudes towards policing.
As the Roman Family Teaching & Research Fellow in the Department of Computer Science, Poliak’s focus on natural language processing — which deals with the interactions between computers and human language — drove him and his research collaborators to quantify public interest in police reform using internet search data.
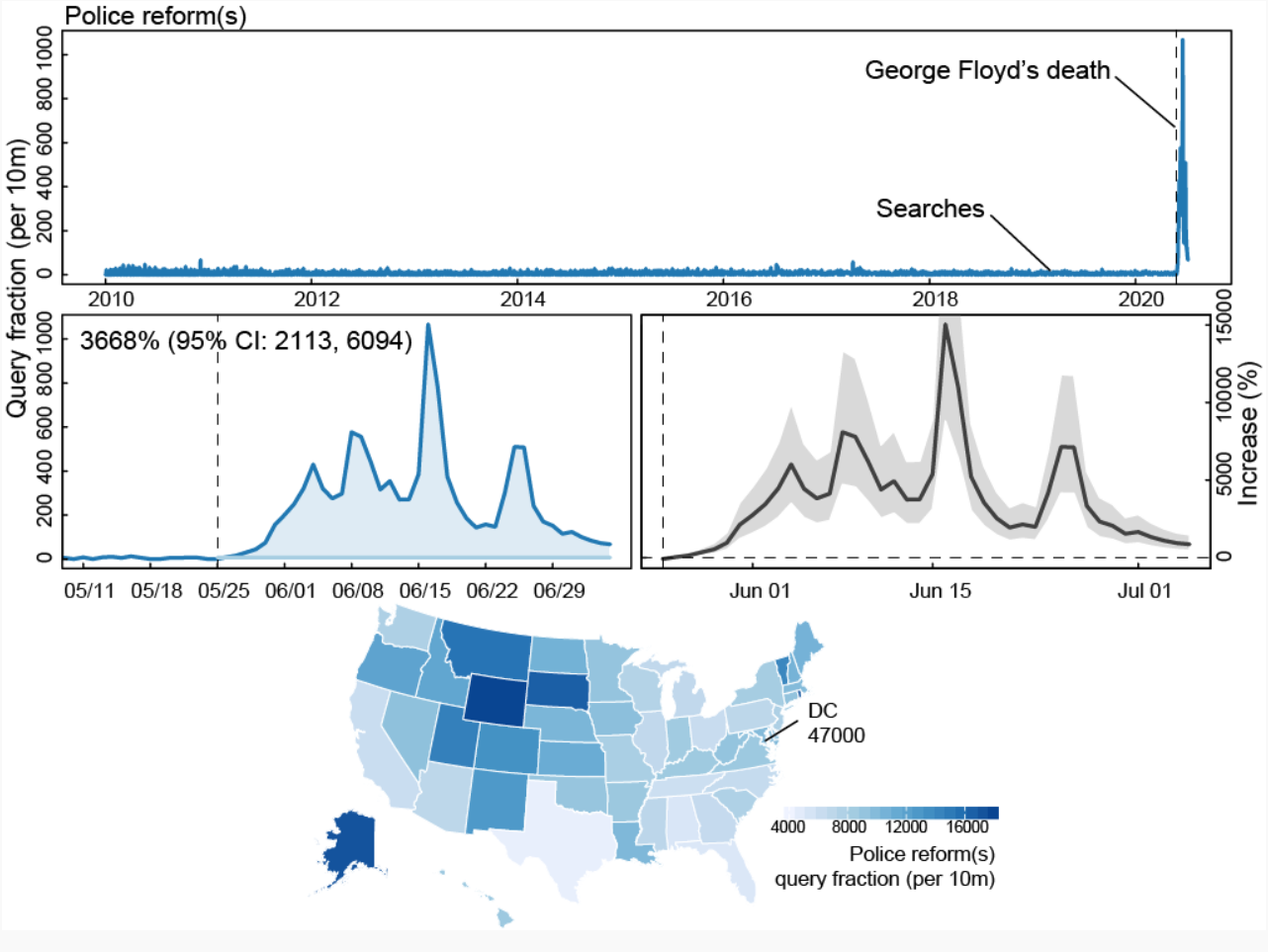
The resulting paper shows that in the 41 days following Floyd’s death, there was a 150-fold increase in Google searches for specific policing-related queries, with data strongly suggesting that the public has a growing interest in police reform. To learn more about Poliak’s natural language processing research and what students interested in his field can do to get hands-on experience, read the “5 Questions With …” interview below.
How did you land on this research topic, and how does it connect to your previous work?
My research focuses on evaluating the reasoning capabilities of natural language processing (NLP) systems. Advances in NLP capabilities made technologies like Google Translate and Apple’s Siri ubiquitous in our lives. Despite the commercial success of these technologies, NLP systems often make mistakes that can perpetuate societal biases or even lead to diplomatic scandals. For example, dialogue systems like Amazon Alexa often fail to understand non-white American accents, and Facebook translated Chinese President Xi Jinping’s name into an expletive when he visited Burma earlier in the year.
Understanding where and why NLP systems fail is vital to making NLP systems that are more fair, equitable, and accessible. This can prevent systems deployed in the real world from further perpetuating damaging biases. Therefore, I develop diagnostic test suites composed of fine-grained semantic phenomena to probe reasoning capabilities of contemporary NLP models. This [process] led me to discover biases in both NLP models and datasets.
A large part of my Ph.D. was sponsored by DARPA’s Low Resource Languages for Emergent Incidents (LORELEI) program, for which I developed NLP models to detect emergency needs during disaster events based on Twitter data. However, I ran into issues related to biases in the dataset that led to biases in my models, prompting me to develop and employ advanced methods to help models overcome biases.
Working on real-world data from social media sparked my interest in using NLP techniques to discover insights and trends from large amounts of text. Through my affiliation at Columbia’s Data Science Institute, I recently started a collaboration with Caitlin Dreisbach, a registered nurse and postdoctoral research scientist, using social media to explore the impacts of COVID-19 on frontline workers and healthcare providers. Additionally, with collaborators at the Johns Hopkins Center of Excellence in Regulatory Science and Innovation and the Qualcomm Institute’s Center for Data Driven Health at the University of California, San Diego, I am working on a federally funded project discovering new e-cigarette tobacco products that are popular on social media. This collaboration is what led to the research topic of discovering search trends about police reform.
What were the key findings of this paper?
In the 41 days following George Floyd’s death, searches for police “reform(s)” hit record highs, eclipsing past searches for police reform by over 150-fold. This translates into about 1,350,000 total searches for police reform, with searches increasing in all 50 states and Washington, D.C.
We monitored searches that mentioned “police” in combination with “immunity,” “union(s),” “training,” or “militarization” — all popular police reform areas that have become increasingly part of the national conversation. We evaluated how search volumes changed following the killing of Floyd by comparing the search volumes that we observed to what would have been expected from historical patterns.
Searches for specific reform topics also set new national benchmarks. Searches for “police” along with “union(s)” eclipsed the past all-time highs by 4.5-fold, “training” by 4.8-fold, “immunity” by 53-fold, and “militarization” by 34-fold. This translates into about 1,220,000 total searches for “union(s),” 820,000 for “training,” 360,000 for “immunity,” and 72,000 for “militarization.”
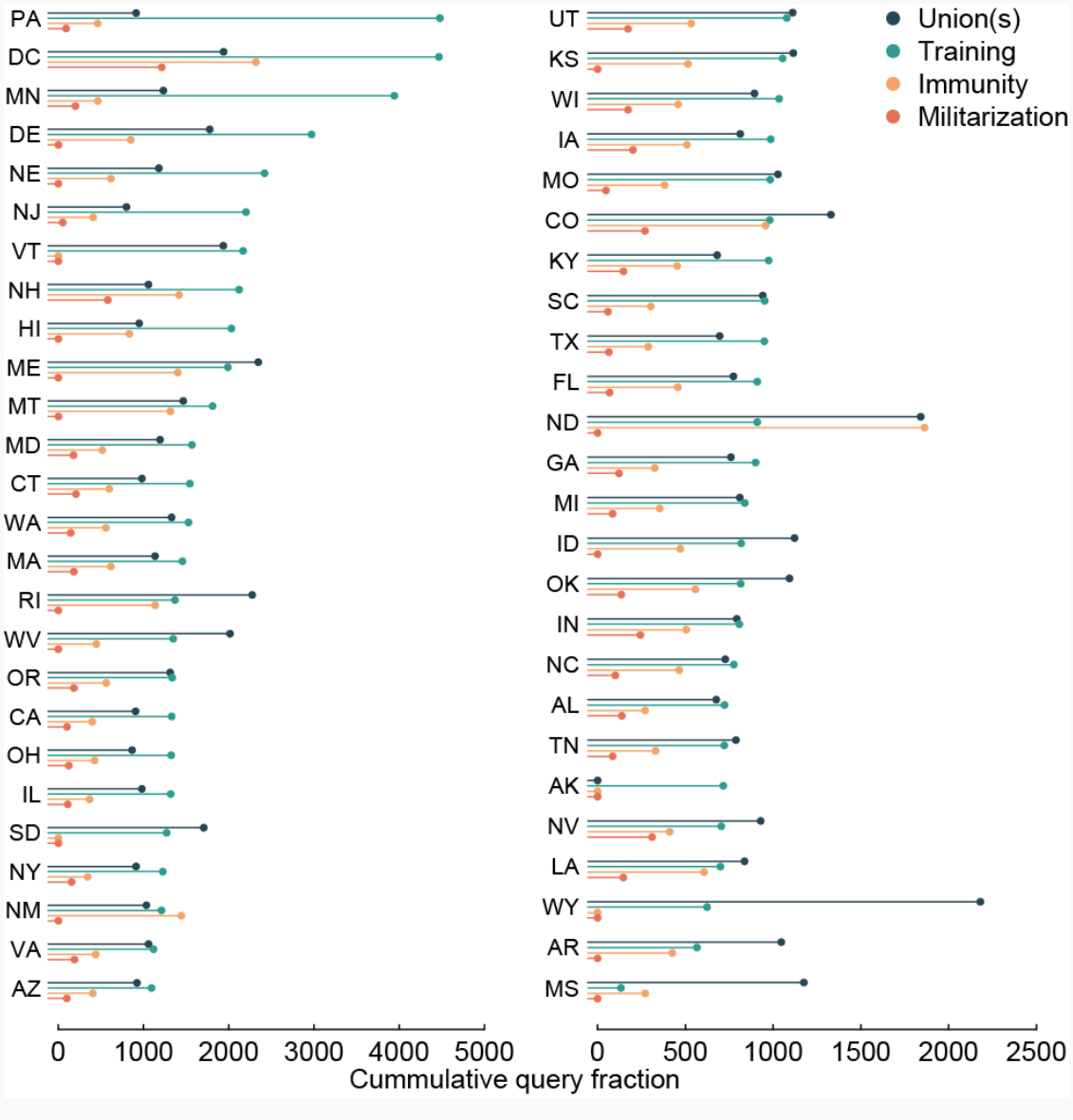
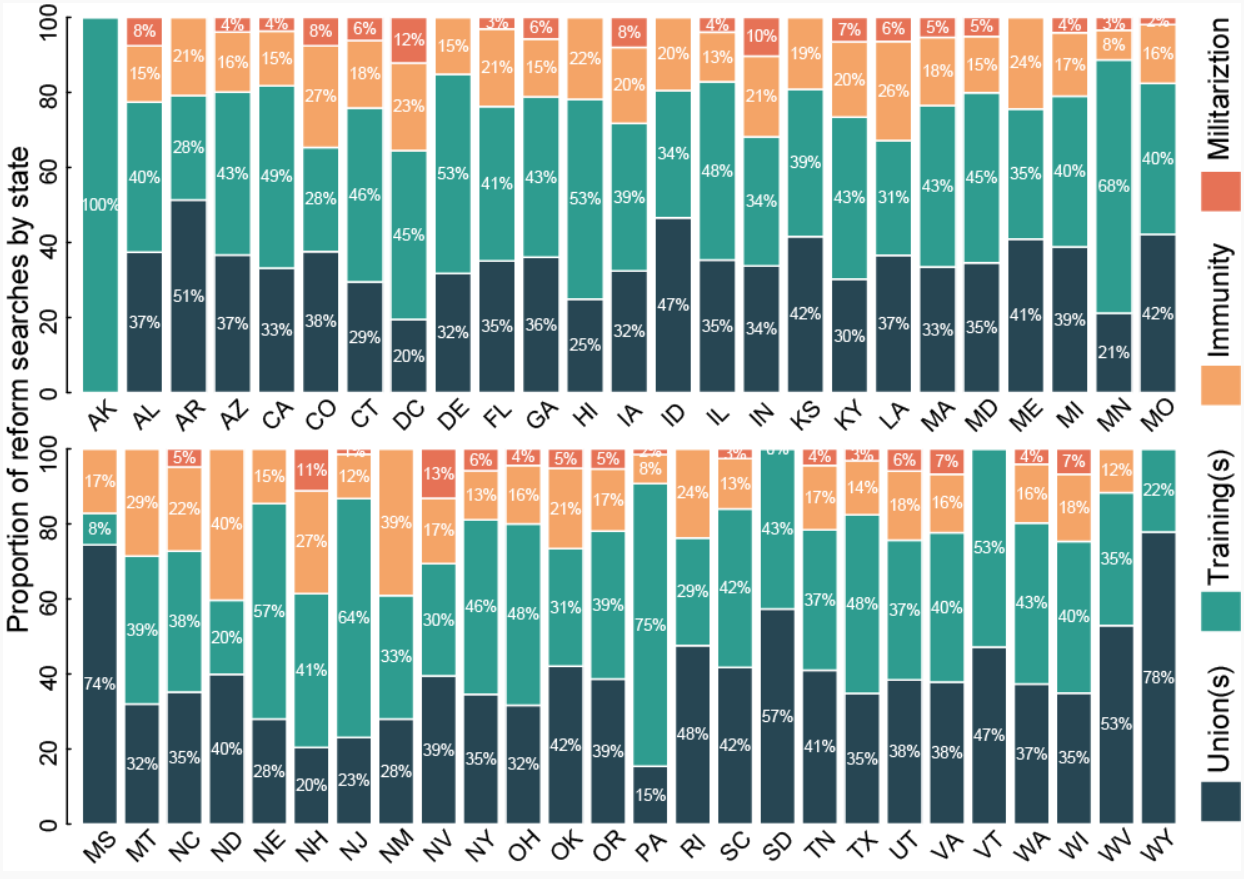
An interesting finding is how searches differed by state. Thirty-three states searched for police “training” more than any other reform topic, including Arkansas, Pennsylvania, Minnesota, and New Jersey. Sixteen states searched more for police “union(s)” than any other reform topic, including Wyoming, Mississippi, South Dakota, and West Virginia. Only two states searched more for police “immunity” (North Dakota and New Mexico), and no states searched more for police “militarization” than all other topics.
We also saw differences emerge across the 2016 U.S. presidential election results. States won by Donald Trump during the 2016 presidential election had a greater proportion of total searches for police “union(s)” (57%), compared with states won by Hillary Clinton, which searched more for police “training.”
What does search data tell us about people, and what can we do with that information?
Search data can tell us a lot about a population much faster than traditional methods used to survey a population. For example, search data can help us discern rising interests in specific topics and assess the needs of a population in real time. Earlier in the year, using search data, we discovered the rise in acute anxiety during the COVID-19 pandemic. Search data has been used to identify an increase in teenage suicide ideation around the release of the Netflix series 13 Reasons Why, to determine the effect that Charlie Sheen’s public HIV diagnosis had on sales for rapid testing kits, and even to track the spread of diseases.
In this paper, the search trends for different states highlight how states have varying needs. Local policymakers can use state-specific trends to find the types of reforms that are best suited to their constituents’ needs, instead of adopting nationwide policies that might be not best for their specific constituents.
What drew you to pursue computer science research?
A research career in an academic setting gives me independence in terms of setting my own research agenda. While there is lots of research in the industry, especially at big tech companies, working in tech often revolves around developing and pushing products that a user will pay for. I appreciate the freedom to focus on research that I find interesting and exciting but that does not have an obvious immediate payout. A career in computer science research allows me to think about long-term research questions and devote time to projects that have a long-term horizon. It is a bonus when my research community finds these ideas exciting as well.
During my last year of undergrad, I joined a great research lab where I worked closely with a professor and his Ph.D. students. Johns Hopkins — where I went for undergrad — had a program similar to Barnard’s Accelerated 4+1 Pathways, and I used that fifth year to immerse myself in a research environment. I was able to take just a few courses and devote a good amount of time to research. I ended up staying at Hopkins for my Ph.D. and working with the same advisor. I was fortunate to be surrounded by a great group of peers who were similarly passionate about NLP research. Every day I learned something new from my fellow Ph.D. students.
What advice do you have for students interested in your field?
Students interested in NLP, machine learning, or data science should start by taking an intro class at Barnard and Columbia, like my fall course Intro to Computational Thinking & Data Science. Being comfortable with the fundamentals of programming and math — in particular, statistics and linear algebra — is important. An innate curiosity is equally helpful. Programming and math are tools to help with problem-solving, but curiosity often leads to identifying a problem or asking an interesting or new research question.
At Barnard and Columbia, students have great opportunities to get hands-on research experience. There are great faculty and graduate students in NLP here that are excited to work with undergrads. I’d encourage any students interested in the field to work with and learn from local experts. Data science is very practical, and students can explore the field in industry as well — there are many companies that are putting NLP and data science tools and techniques to practice.
I’d also tell students to try being comfortable in new experiences. Entering a new field can be daunting, so students should be confident to unapologetically seek out mentors. The students in my courses at Barnard know that I won’t let them apologize for asking questions or taking advantage of the resources and support we offer.
Lastly, data science is a team sport. We often imagine a researcher working in isolation for years, but most work in the field is done collaboratively. Have a can-do attitude and be ready to engage others. Although students might be new to the field, they still have a lot to offer. In my small, hands-on research class (BC COMS 3997), I am constantly learning from my students, and their questions and curiosities lead to different research directions.


